Building a Production RAG System: From Hybrid Search to Agentic Retrieval
There’s no shortage of RAG tutorials online, but most stop at the “hello world” stage: embed some documents, throw them into a vector database, retrieve top-k, and feed them to an LLM. That works for demos. It falls apart in production.
I’ve been building a RAG system at work — one that searches across thousands of internal documents (engineering issues, SDK source code, design specs, technical docs) and serves results to LLM agents via MCP. I can’t go into the specifics of the product or infrastructure, but the technical challenges and lessons are universal enough to share.
This post covers what I learned along the way: hybrid search with RRF, why rerankers can actually hurt quality, Q&A-augmented chunking, and the shift toward agentic retrieval.
The Standard RAG Pipeline (and Its Limits)
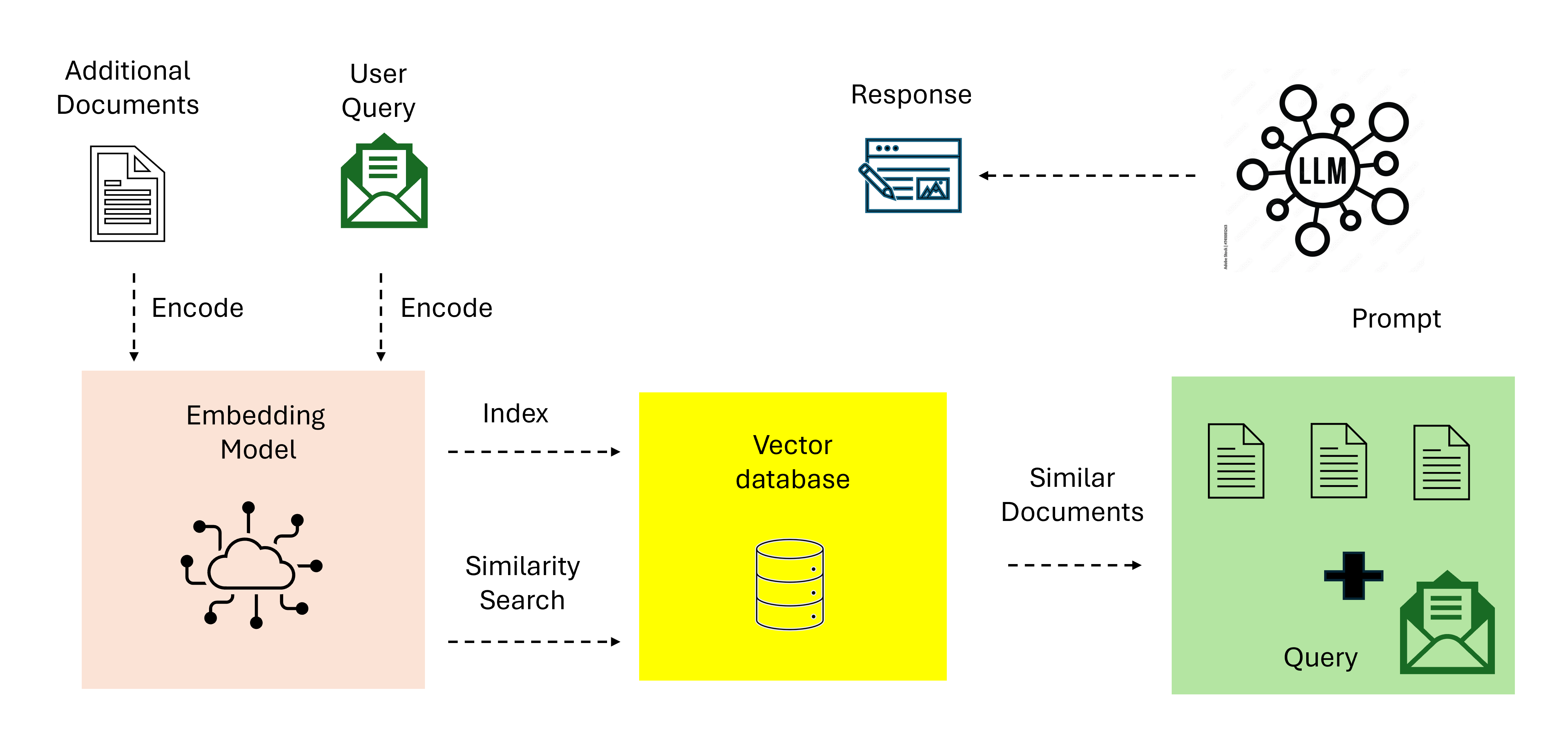
The canonical RAG architecture looks like this:
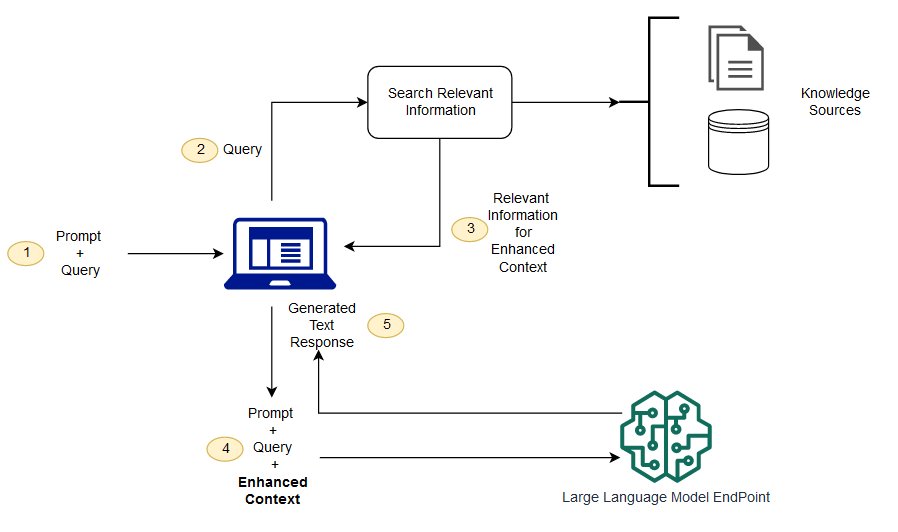
The original RAG paper by Lewis et al. (2020)1 demonstrated that combining retrieval with generation outperforms purely parametric models on knowledge-intensive tasks. The idea is simple: instead of expecting the LLM to memorize everything, give it a search engine.
But “naive RAG” — a single embedding model, a single vector search, top-k retrieval, and a prompt — has well-documented failure modes:
- Vocabulary mismatch: Dense embeddings capture semantics but miss exact keywords. Searching for
ISSUE-1234with a dense vector won’t find an exact match. - Lost in the middle: LLMs tend to ignore context in the middle of long prompts2. Stuffing 20 chunks into the context window often degrades answer quality.
- Chunking artifacts: Splitting documents at arbitrary boundaries breaks context. A key sentence might be split across two chunks.
The survey by Gao et al. (2024)3 categorizes RAG evolution into three paradigms: Naive RAG, Advanced RAG (pre/post-retrieval optimization), and Modular RAG (pluggable, composable components). What I built falls somewhere between Advanced and Modular.
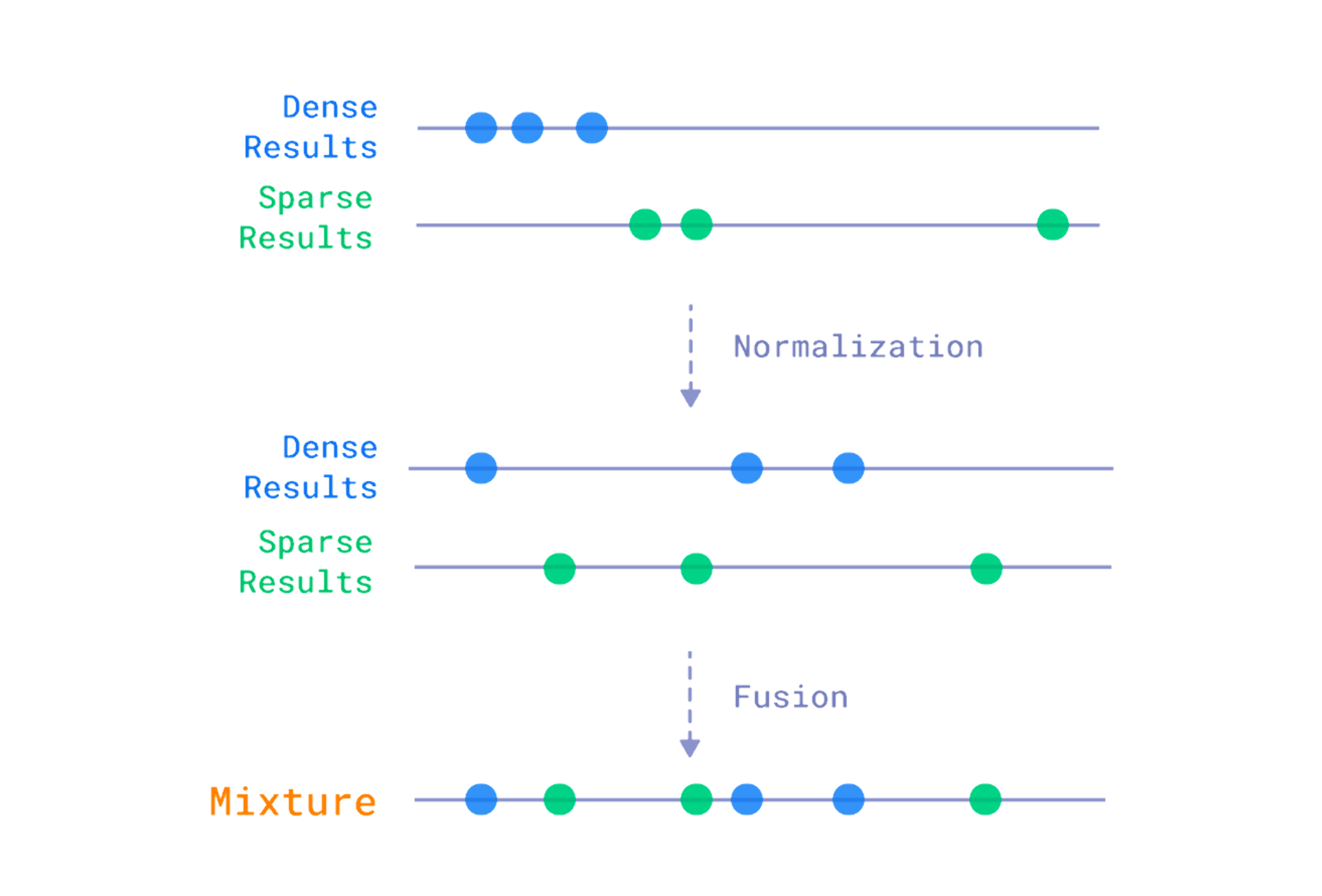
Hybrid Search: Dense + Sparse with RRF
The single biggest quality improvement in my system came from hybrid search — combining dense vector retrieval with sparse keyword matching.
Why Not Just Dense Vectors?
Dense embeddings are great at capturing semantic similarity. “How to fix buffering issues” and “Troubleshooting playback stuttering” will have high cosine similarity even though they share no keywords. But dense search fails on:
- Exact identifiers: Issue keys like
BUG-1234, class names likeHttpConnectionPool, error codes - Rare domain terms: Internal jargon, acronym-heavy technical discussions
- Short queries: A 2-word query produces a vague embedding
The Sparse Side
Sparse vectors (BM25 or learned sparse models like SPLADE4) excel at exact keyword matching. They represent text as high-dimensional sparse vectors where each dimension corresponds to a vocabulary token. The key insight: sparse and dense retrieval have complementary failure modes.
I used a simple approach: FNV-1a hashing for token-to-dimension mapping with sublinear TF scaling. Not as sophisticated as SPLADE, but fast and effective for domain-specific text.
Reciprocal Rank Fusion (RRF)
The question is: how do you combine results from two different ranking systems? RRF5 is remarkably simple and effective:
$$\text{RRF}(d) = \sum_{r \in R} \frac{1}{k + r(d)}$$Where $r(d)$ is the rank of document $d$ in ranking $r$, and $k$ is a constant (typically 60). RRF doesn’t care about raw scores — it only uses rank positions. This makes it robust to score distribution differences between dense and sparse retrievers.
In practice, hybrid search consistently outperformed either method alone in my benchmarks. The improvement was most dramatic for queries that mixed natural language with identifiers: “HTTP connection pool exhausted with error code 23”.
The Reranker Trap
Cross-encoder rerankers are the standard “Advanced RAG” recommendation. Retrieve a broad set of candidates, then rerank them with a more powerful model that sees query-document pairs jointly.
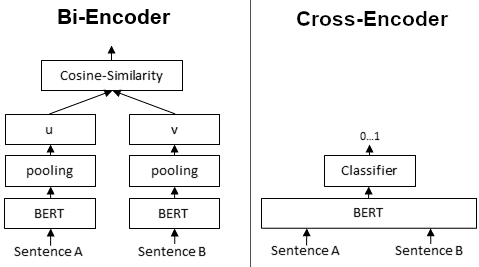
The theory is sound. Bi-encoders (used in the retrieval stage) embed queries and documents independently — they can’t model fine-grained interactions. Cross-encoders see both together, enabling richer attention patterns6.
When Rerankers Hurt
Here’s what the tutorials don’t tell you: rerankers can degrade quality. I ran a comprehensive A/B test across 540 queries spanning 5 different document collections. The results:
| Metric | Without Reranker | With Reranker |
|---|---|---|
| Hit@1 | 58.3% | 43.0% |
| Hit@3 | 75.6% | 66.0% |
The reranker made things significantly worse. Why?
- Domain mismatch: The reranker was trained on general web text, not on a mix of code, issue trackers, and technical specs. It confidently reranked code snippets lower because they “didn’t look like” good answers to natural language queries.
- Already-good retrieval: Hybrid search was already doing a good job. When your first-stage retrieval is strong, the reranker has less room to improve and more room to introduce errors.
- Collection diversity penalty: The reranker flattened results from multiple heterogeneous collections into a single ranking. Domain-specific results from smaller collections got pushed down.
The lesson: always A/B test your reranker on your actual data. Don’t assume it helps because it helps on BEIR benchmarks. Even Sun et al. (2023)7, who showed GPT-4 is competitive as a listwise reranker, found significant variance across datasets — reranking gains are not universal.
I kept the reranker code in the system but disabled it by default, with a flag to re-enable for future model evaluations.
Q&A-Augmented Chunking
One of the most effective techniques I found was generating synthetic Q&A pairs from each document chunk using an LLM, then indexing the questions alongside the original content.
The Query-Document Mismatch Problem
Users ask questions: “How do we handle connection timeout issues?” Documents contain statements: “RetryPolicy applies exponential backoff after the first failure and uses a configurable max retry count.”
The semantic gap between a question and a declarative statement is real. Even good embedding models partially suffer from this mismatch.
The Fix: Index Questions, Not Just Answers
For each chunk, I generated 2-3 Q&A pairs using an LLM:
Source chunk: "RetryPolicy applies exponential backoff after the first
failure. The max retry count is configurable via setMaxRetries(n)."
Generated Q&A:
Q: How does the system handle failed requests?
A: RetryPolicy applies exponential backoff after the first failure,
progressively increasing delay between attempts.
Q: How can I configure the retry limit?
A: Use setMaxRetries(n) to set the maximum number of retry attempts.
These Q&A pairs get embedded and indexed as separate points in the vector database, with a chunkType=qa metadata tag. When a user asks a question, the semantic similarity between their query and the generated question is much higher than with the raw document text.
This approach aligns with recent work on synthetic data in RAG systems. Wang et al. (2024)8 showed that LLM-generated synthetic data can significantly improve embedding model quality, and RAFT (Zhang et al., 2024)9 demonstrated that training generators with domain-specific Q&A pairs (alongside distractor documents) improves answer extraction from retrieved results. The same intuition applies to the retrieval side: if you index the questions users are likely to ask, embedding similarity improves at search time.
In my benchmarks, Q&A chunks appeared in the top-3 results for 29% of all queries — a meaningful contribution on top of the original document chunks.
Serving RAG Through MCP
With the retrieval system working, the question became: how do you expose it to LLM agents?
Why MCP?
The Model Context Protocol is an open standard (by Anthropic) that defines how LLMs interact with external tools and data sources. Think of it as a standardized API layer between the LLM and your services.
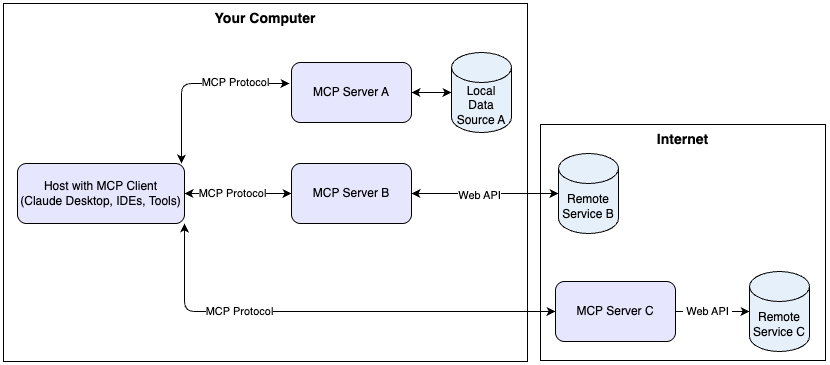
MCP defines three primitives:
- Tools: Functions the model can call (e.g.,
search,list_collections) - Resources: Contextual data the model can read
- Prompts: Templated interaction patterns
The key advantage over a custom API: any MCP-compatible client (Claude Code, Cursor, etc.) can connect to your server without custom integration code. It’s the “USB-C for AI tools” analogy10.
Stdio vs. HTTP Transport
MCP supports two transports as defined in the Streamable HTTP specification:
| Stdio | Streamable HTTP | |
|---|---|---|
| Deployment | Local process | Remote server |
| Multi-client | No | Yes |
| Auth | OS-level | HTTP standard (Bearer, OAuth) |
| Use case | Developer’s machine | Team-wide shared service |
I implemented both: stdio for local development (the default), and Streamable HTTP for container deployment. The HTTP mode enables serving the RAG system as a shared team resource — and opens the door for building a web-based inspector UI on top.
The official MCP Rust SDK (rmcp) natively supports Streamable HTTP via its transport-streamable-http-server feature, so no custom HTTP layer was needed.
Toward Agentic RAG
The system described so far is still “Advanced RAG” — the retrieval logic is hardcoded. The LLM calls search and gets results, but it doesn’t decide whether to search, how to search, or whether the results are good enough.
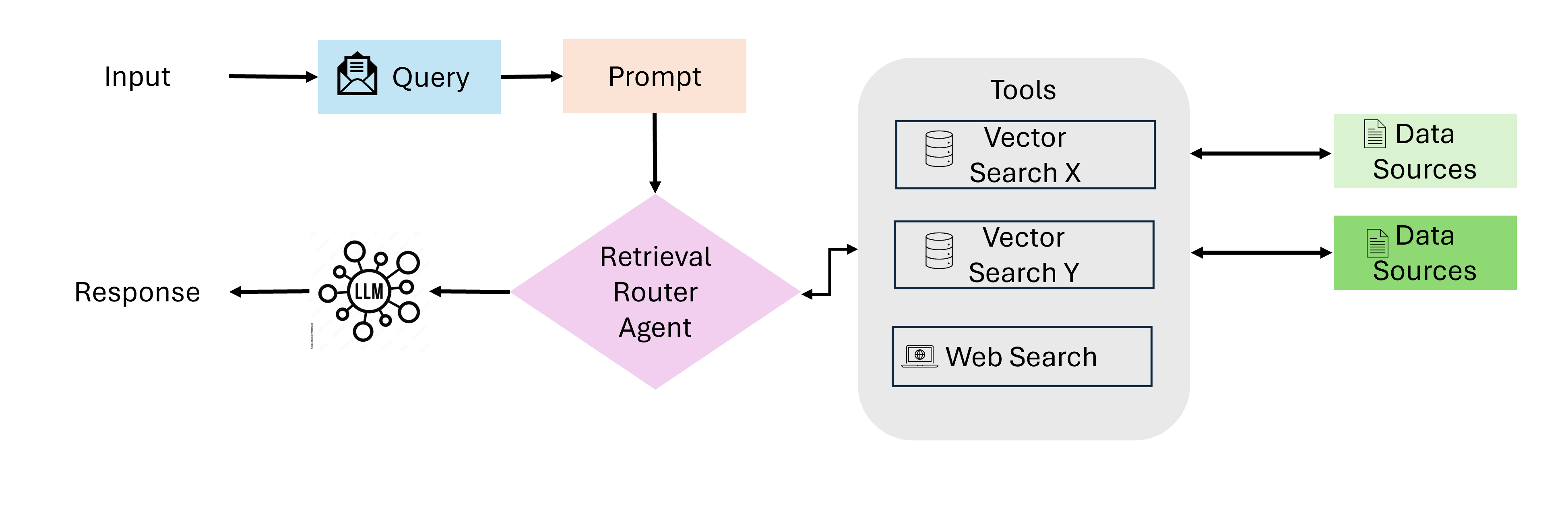
Recent research points toward Agentic RAG, where the LLM itself becomes an active participant in the retrieval process:
- Self-RAG (Asai et al., 2024)11: The model generates “reflection tokens” to decide when retrieval is needed and whether retrieved content is relevant.
- CRAG (Yan et al., 2024)12: A “retrieval evaluator” scores relevance and triggers web search as a fallback when local retrieval fails.
- Adaptive-RAG (Jeong et al., 2024)13: Routes queries to different retrieval strategies based on complexity.
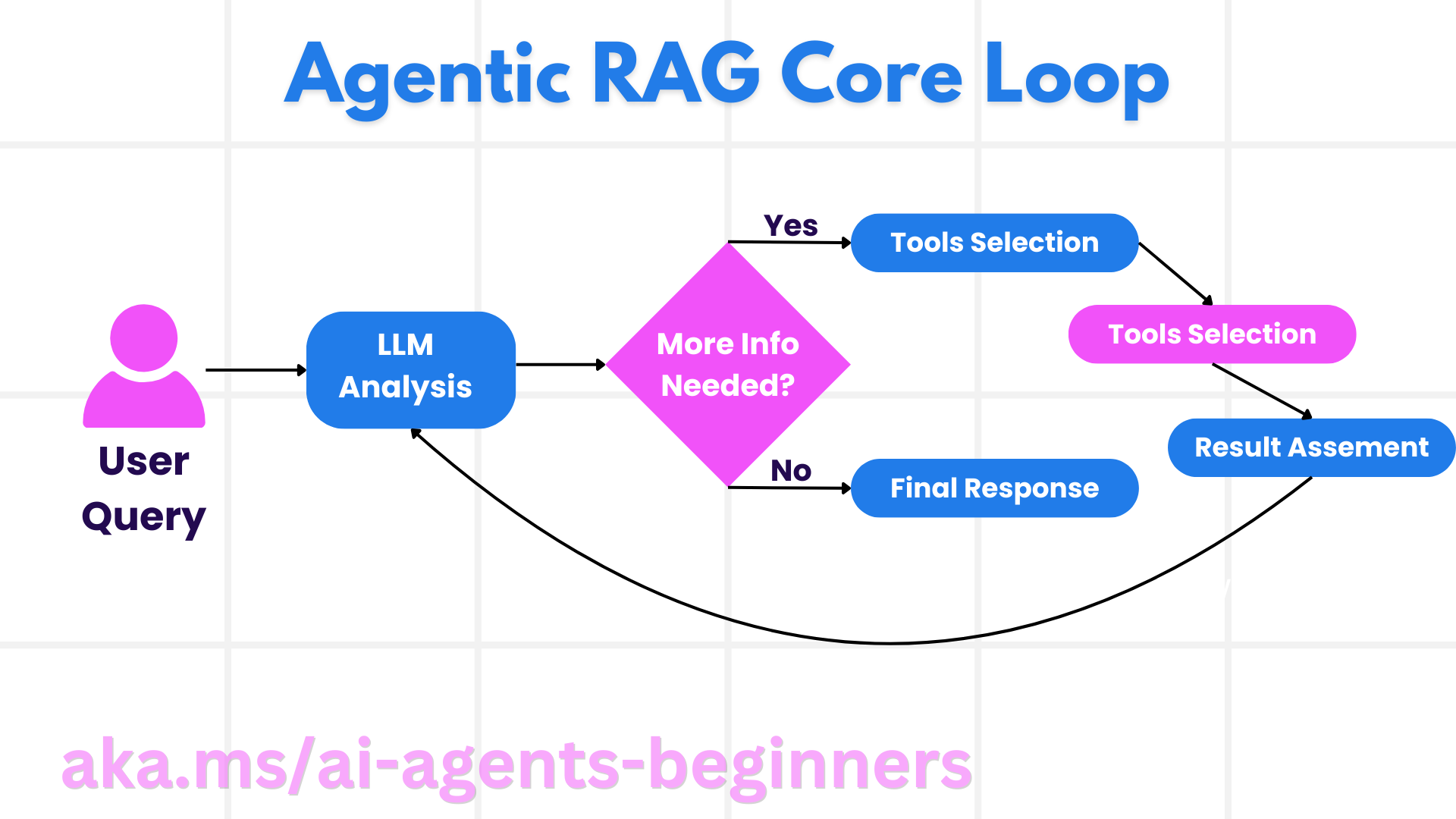
In practice, MCP already enables a lightweight form of agentic RAG: the LLM can call list_collections to understand what data is available, then decide which search query to issue, evaluate the results, and retry with different keywords if needed. The “agent” behavior emerges from the LLM’s own reasoning, guided by the server’s instructions.
The next step is making this more explicit — adding query classification tools, relevance scoring, and multi-hop retrieval capabilities.
Containerization for Production
A RAG system is only useful if people can actually use it. Mine started as a local binary — you’d install it via a package manager and run it on your own machine. That works for one person, but it doesn’t scale to a team. Containerizing it and deploying to a Kubernetes-based platform turned it from “my tool” into “the team’s tool.”
The Rust Docker Problem
Docker layer caching and Rust don’t play well together by default. cargo build treats dependency compilation and your source code compilation as one unit. Change a single line of your code? Every dependency gets recompiled. For a project with 200+ transitive dependencies, that means 10+ minute builds on every push.
cargo-chef solves this with a three-stage build:
# Stage 1: Analyze dependency graph
FROM rust:1.88-alpine AS planner
RUN cargo install cargo-chef --locked
WORKDIR /build
COPY . .
RUN cargo chef prepare --recipe-path recipe.json
# Stage 2: Build dependencies (this layer is cached!)
FROM rust:1.88-alpine AS builder
RUN cargo install cargo-chef --locked
WORKDIR /build
COPY --from=planner /build/recipe.json recipe.json
RUN cargo chef cook --release --recipe-path recipe.json
# ↑ Only re-runs when Cargo.toml or Cargo.lock changes
# Now build the actual application
COPY . .
RUN cargo build --release
# Stage 3: Minimal runtime (~20MB)
FROM alpine:3.23
RUN apk add --no-cache ca-certificates curl tini
COPY --from=builder /build/target/release/my-server /usr/local/bin/
ENTRYPOINT ["/sbin/tini", "--"]
CMD ["my-server", "--http", "--port", "8080"]
The key idea: cargo chef prepare generates a recipe.json that captures the dependency graph without your source code. Docker caches the cargo chef cook layer as long as recipe.json doesn’t change. When you push a code-only change, Stage 2 is a cache hit and only the final cargo build runs — bringing rebuild times from ~10 minutes down to ~1 minute.
The final image ends up around 20MB. The Rust binary is statically linked against musl (thanks to the Alpine base), so the runtime stage needs almost nothing — just CA certificates for HTTPS and tini for signal handling.
Health Checks: Liveness vs. Readiness
Kubernetes uses two distinct health probes, and getting them wrong causes real outages:
Liveness probe: “Is the process alive?” If this fails, Kubernetes kills and restarts the container. A simple
/healthendpoint returning200 OKis enough. Don’t put dependency checks here — if your database is down, restarting your pod won’t fix it. You’ll just get a crash loop.Readiness probe: “Can this pod handle traffic?” If this fails, the pod is removed from the load balancer but not restarted. This is where you check if the service has finished initialization (e.g., loading embedding models, connecting to the vector database).
async fn health_handler() -> axum::Json<serde_json::Value> {
axum::Json(serde_json::json!({
"status": "ok",
"version": env!("CARGO_PKG_VERSION"),
"transport": "http"
}))
}
In my case, I used the same /health endpoint for both probes but with different timing: readiness checks every 10 seconds (catch fast failures), liveness every 30 seconds (don’t restart too aggressively).
Graceful Shutdown: Why tini Matters
When Kubernetes wants to replace your pod (rolling update, scale-down, node drain), it sends SIGTERM and gives you a grace period (default 30 seconds) to finish in-flight requests. If your process doesn’t handle SIGTERM, Kubernetes escalates to SIGKILL — instant death, dropped connections, possibly corrupted state.
Two things make this work:
tini as PID 1: Docker runs your
ENTRYPOINTas PID 1, but most applications aren’t designed to be PID 1 — they don’t reap zombie child processes or forward signals. tini is a tiny init process that handles this correctly. It forwardsSIGTERMto your application and reaps zombies.Application-level shutdown: In the async runtime, a
CancellationTokenpropagates the shutdown signal. WhenSIGTERMarrives, the token is cancelled, which tells the HTTP server to stop accepting new connections and drain existing ones:
async fn shutdown_signal(ct: CancellationToken) {
let ctrl_c = async {
tokio::signal::ctrl_c().await.expect("failed to install Ctrl+C handler");
};
let terminate = async {
tokio::signal::unix::signal(SignalKind::terminate())
.expect("failed to install SIGTERM handler")
.recv()
.await;
};
tokio::select! {
_ = ctrl_c => {},
_ = terminate => {},
}
ct.cancel(); // propagates to HTTP server → graceful drain
}
Without this, I was seeing occasional 502 Bad Gateway errors during deployments — the old pod would get killed mid-request before the new pod was fully ready. With proper shutdown handling and readiness probes, deployments became zero-downtime.
Lessons Learned
Building this system at work — from the first prototype to a containerized service the team actually uses — taught me things that no tutorial covers. Here’s what I’d tell someone starting from scratch:
Start with hybrid search. Dense-only retrieval is a trap for domain-specific data. Adding sparse keyword matching with RRF is cheap and effective.
Benchmark before adding a reranker. Don’t assume rerankers help. A/B test on your actual queries and documents. If your first-stage retrieval is already strong, the reranker might just add latency and errors.
Q&A augmentation is underrated. Generating synthetic questions from your documents is one of the highest-ROI techniques. It directly addresses the query-document semantic gap.
Use a standard protocol. Building a custom API for your RAG system locks you into one client. MCP (or similar standards) lets any compatible agent connect without integration work.
Zero-config is worth the effort. Auto-discovering collections, inferring metadata fields, and providing sensible defaults means users don’t need to understand your infrastructure to get value from it.
Containerize early. The difference between “works on my machine” and “works for the team” is a Dockerfile and a health endpoint.
References
Lewis, P., et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” NeurIPS 2020. arXiv:2005.11401 ↩︎
Liu, N., et al. “Lost in the Middle: How Language Models Use Long Contexts.” TACL 2024. arXiv:2307.03172 ↩︎
Gao, Y., et al. “Retrieval-Augmented Generation for Large Language Models: A Survey.” 2024. arXiv:2312.10997 ↩︎
Formal, T., et al. “SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval.” 2022. arXiv:2109.10086 ↩︎
Cormack, G., Clarke, C., & Buettcher, S. “Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods.” SIGIR 2009. ↩︎
Reimers, N. & Gurevych, I. “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks.” EMNLP 2019. arXiv:1908.10084 ↩︎
Sun, W., et al. “Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents.” 2023. arXiv:2304.09542 ↩︎
Wang, L., et al. “Improving Text Embeddings with Large Language Models.” 2024. arXiv:2401.00368 ↩︎
Zhang, T., et al. “RAFT: Adapting Language Model to Domain Specific RAG.” 2024. arXiv:2403.10131 ↩︎
Anthropic. “Introducing the Model Context Protocol.” November 2024. anthropic.com ↩︎
Asai, A., et al. “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection.” ICLR 2024. arXiv:2310.11511 ↩︎
Yan, S., et al. “Corrective Retrieval Augmented Generation.” 2024. arXiv:2401.15884 ↩︎
Jeong, S., et al. “Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity.” NAACL 2024. arXiv:2403.14403 ↩︎
#RAG #vector-search #MCP #hybrid-search #reranker #agentic-rag #LLM